
Bildquelle Beitragsbild: Image by Anja from Pixabay

CRISP DM – (Cross Industry Standard Process for Data Mining) – und wie man es im Unternehmen nutzt.
Schon 1996 wurde das CRISP-DM Modell konzipiert und 1997 ein EU-Projekt, gefördert nach dem ESPRIT-Programm, gestartet. Die Zielsetzung dieses Data Mining Modells ist , einen branchen-, software- und anwendungsunabhängigen Prozessablauf für Data Mining zu finden. Damit soll ein möglichst hoher Qualitätsstandard im Umgang mit Daten, also beim Erheben, Speichern, Verarbeiten und Analysieren gefunden werden. Es geht also, um
- die Schaffung eines einheitlichen Prozess- und Vorgehensmodells bei Data Mining Projekten
- das Finden der relevanten Datenbestände für beliebige geschäftsrelevante Aufgabenstellungen
- die Festlegung der Grundlage für Wissensgewinnung aus Daten (Knowledge Mining)
- das Aufbauen einer datengetriebenen Entscheidungskultur über alle Management-Ebenen hinweg
- eine branchenunabhängige Nutzung des Modells für des Austausch von Erfahrung und Fachwissen
- das Finden und den Aufbau von neuen. datengetriebenen Geschäftsmodellen
Obwohl das Modell doch an die 30 Jahre bekannt ist, ist es nach wie vor aktuell – vielleicht aktueller den je – denn mit den neuen Technologien rund um das Cloud Computing, das Internet der Dinge (IoT), Künstliche Intelligenz (AI) und dezentrale Organisationsstrukturen (Blockchain) gewinnen Daten enorm an Bedeutung. Sie werden zu einem unumstößlichen Wettbewerbsfaktor. Hier standardisierte Prozesse im Umgang mit Daten im Unternehmen zu etablieren ist nicht nur eine Frage der Professionalität und Moderne ihrer Unternehmensorganisation, sondern wahrscheinlich eine pure Frage des Überlebens!
Die 6 Phasen des CRISP-Modells
Im Folgenden wird das Framework des CRISP-DM-Prozesses dargestellt. In sechs Schritten, welche wir Phasen nennen, ist dieser segmentiert ist. Generell sei gesagt, dass das CRISP-DM-Modell als inkrementell, iterativ zu verstehen ist. Einmal in Gange gesetzt wird es ständig weiter entwickelt und die einzelnen Phasen werden nach notwendiger, unterschiedlicher Gewichtung immer wieder durchgearbeitet. So schafft man am Ende Excellence im Data Mining. Jede Phase dieses Modells spielt eine entscheidende Rolle für eine erfolgreiche Projektumsetzung im Data Mining.
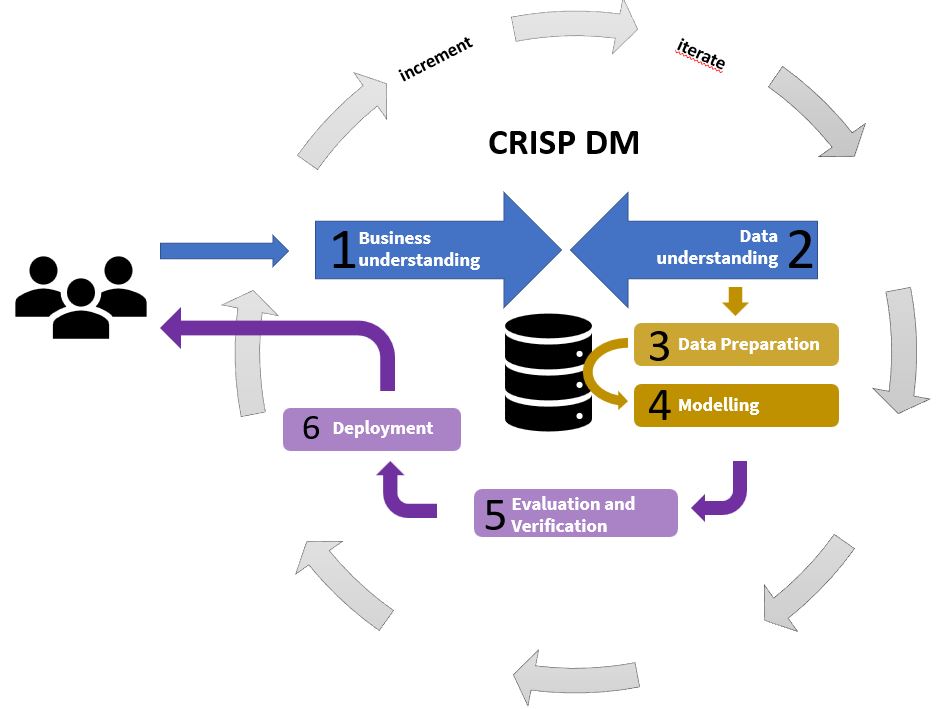
Bildquelle CRISP-DM Modell nach Shear: MBe-consulting e.U.
Der äußere Prozesskreis zeigt einen Kreislauf, der die inkrementelle Iteration im Projektfortschritt darstellen soll, und die innere Folge der Aufgaben modelliert die flexible Prozessarchitektur der Phasen, die nicht in einer starren Sequenz abläuft, sondern Rückkopplungen erlaubt, wenn sich die Zwischenergebnisse nicht zufriedenstellend einstellen. Schauen wir nun auf den Arbeitsinhalt der einzelnen Phasen:
Phase 1: Business Understanding – Auftragsdefinition
Die Arbeiten in Phase 1 konzentrieren sich darauf, den Projektinhalt zu verstehen. Hierbei ist es wichtig, einerseits mit allen Stakeholdern das Projekt eindeutig zu definieren und ganz besonders den Anwender intensiv mit einzubeziehen, um ein Verständnis der Fragestellung des Projektes zu entwickeln. Der Anwender weiß am Ende am Besten, was er mit den Ergebnissen tut, wie er die Daten und die daraus extrahierten Erfahrungen nutzt. Die Data Engineers müssen klar verstehen, was gemacht werden soll, also das Ziel muss eindeutig definiert werden und es muss ein Grundverständnis zu zumindest folgenden Themen nach Abschluss der Phase 1 vorliegen:
- Die betriebswirtschaftlichen Problemstellung: Hier werden die operationalen und betriebswirtschaftlichen Zielkriterien formuliert. Was will man aus betriebswirtschaftlicher Sicht wissen.
- Risikoanalyse: Es werden Risiken der Umsetzung bestimmt und eventuelle Gegenmaßnahmen (Risikominimierung) definiert.
- Erhebung des Status quo: Es wird erhoben, welche Software- sowie Personalressourcen für das Data Mining-Projekt zur Verfügung stehen.
- Bestimmung analytischer Ziele: Ausgehend von der zuvor bestimmten betriebswirtschaftlichen Problemdefinition müssen dazu die erforderlichen Datenanalyseaufgaben ermittelt werden. Zudem müssen die Erfolgskriterien für das Data Mining-Projekt bestimmt werden. Diese Erfolgskriterien müssen auch messbar sein!
- Geschäftsmodell: Soll mit dem Projektziel auch ein Geschäftsmodell verbunden sein, so ist es notwendig, dieses hier auch zu beschreiben. Es lohnt sich dafür z.B. ein Business Canvas durchzuführen (Wer erhält was, wie zu welchem Wert).
- Erstellung des Projektplans: Der Projektplan beschreibt die beabsichtigten Ziele des Data Mining-Projektes. Arbeitspakete, Projektstruktur und Zeit- und Ressourcenplan sind zu erstellen. Wir kennen das ja aus dem Projektmanagement.
Die Phase 1 ist eine Managementaufgabe. Das Projekt, die Aufgabenstellung (Inhalt) wird klar definiert (präzisiert) und die Umsetzung im Unternehmenskontext (Zeit, Ressourcen) wird festgelegt. Widmen sie dieser Phase schon ausreichend Zeit und wie schon oben gesagt: Nicht im stillen Kämmerlein, sondern stimmen sie sich immer mit den Stakeholdern ab, damit das Verständnis über den Leistungsumfang synchronisiert ist. Am Ende dieser Phase wissen sie was, wer, wie zu machen hat und können mit der eigentlichen Umsetzung starten.

Phase 2: Data Understanding – Identifizieren der relevanten Daten
Nach der Formulierung der analytischen Ziele für das Data Mining ist nun eine Auswahl der relevanten Datenbestände zu treffen. Diese Phase dient dem Analysten, bestehende Zusammenhänge aus den Daten zu erkennen, eventuelle Qualitätsmängel der Daten festzustellen oder interessante Teilmengen zu identifizieren, um eine Hypothese über die Daten aufzustellen. Die Phase besteht aus folgenden vier Schritten:
- identifizieren: Der Hauptschritt in dieser Phase. Hier werden die Daten identifiziert die für die Zielerreichung laut Auftragsdefinition notwendig sind. Erst einmal betrachtet man hier die Rohdaten, die entweder schon in internen oder externen Datenquellen vorliegen, oder wo entsprechende Sammelprozeduren noch einzurichten sind. Das ist aber erst einmal noch unerheblich. Es gilt hier die korrekte Datenbasis für die Aufgabenstellung eindeutig zu identifizieren und zu definieren.
- beschreiben: Die Eigenschaften der Daten beschreiben, wie Quantität der Daten, Ort der Ablage, Frequenz der Erhebung, Genauigkeit der Dateninhalte, Formateigenschaften, Anzahl der Einträge und Felder, usw. ist Aufgabeninhalt dieser Phase. Es ergibt sich ein Qualitätsbild zu den notwendigen Datenbeständen und damit kann auch eine Bewertung vorgenommen werden, ob die Aufgabenstellung erreicht werden kann.
Phase 3: Data Preparation – Daten erheben und aufbereiten
Die finale, darstellbare Datenmenge zur Erfüllung der Projektziele herzustellen ist der Kern dieser Phase. Die Rohdaten werden durch die einzelnen Ebenen eines Datawarehouses gefiltert, sortiert, gerechnet um am Ende ein Datenkonvolut zu haben, dass die Nutzer mit Business Intelligence Lösungen darstellen können. Die Tätigkeiten umfassen dabei die Auswahl der Datenbanken und Tabellen, Einträge und Attribute und der Fokus liegt auf der Transformation und Bereinigung der Daten. Es geht also um das …
- Extrahieren der Daten: Aus unterschiedlichen Datenquellen werden die relevanten Daten extrahiert und in Datawarehouse in den STAGING-Bereich übernommen. Das sind grundsätzlich alle Rohdaten, ungefiltert, unbereinigt, unaufbereitet. Damit wird der Zugriff auf die Datensätze für die weitere Verarbeitung vereinfacht und die Daten erzeugenden Echtsysteme (Datenbanken, ERP-Systeme, IoT-Systeme usw.) werden später durch ständige Datenzugriffe nicht belastet.
- Untersuchen der Daten: Die Daten werden dann auf ihre Qualität und Korrektheit geprüft und gegebenenfalls bereinigt. Das passiert automatisiert und Bedarf natürlich vorher erstellter Algorithmen für die qualitative Bewertung der Daten.
- Transformatieren und Integrieren der Daten: Manche Datenfelder müssen dann einer ersten Bearbeitung unterzogen werden. Hier können auch schon einfache Berechnungen erfolgen und in manchen Fällen muss das Datenformat verändert werden. Diese Schritte vereinfachen die spätere Modellierung sind aber meist nicht unaufwendig.
In Data Mining-Projekten wird in der Regel 50%-70% der Zeit für die Datenaufbereitung benötigt. Nur 20%-30% der veranschlagten Zeit entfallen dabei auf die Bestimmung der relevanten Datenbestände. Für die Modellierung, die Bestimmung der betriebswirtschaftlichen Fragestellung und Erfolgsmessung wird jeweils 10%-20% benötigt, lediglich 5%-10% der Zeit entfallen auf die Implementierung der erstellten Modelle.

Phase 4: Modeling – Auswahl und Anwendung von Data Mining Methoden
Jetzt sind wir soweit. Während wir uns von Phase 1-3 nur darum gekümmert haben die Rohdaten auszuwählen und zu sammeln und in eine Form zu bringen die verarbeitbar ist, wird in Phase 4 aus den roh vorliegenden Datentabellen und Datensätzen Information und Wissen, welche dem Management aller Ebenen zielsichere Entscheidungen erlaubt.
Es gibt eine Vielzahl an Modellen (stochastische) die im Data Mining zum Einsatz kommen. Hier kann es sein, dass aufgrund speziell genutzter Methoden, auch die Daten nochmal angepasst werden, Ein iterativer Schritt zurück zu der Phase 3 „Data Preperation“ ist deshalb in der Praxis immer von Nöten:
- Auswahl der Modellierungstechnik: statistische Methoden, Filtertechniken, Künstliche Intelligenz!
- Bewertung des Modells: Die Qualität und Genauigkeit des Data Mining-Modells muss überprüft werden. Es benötigt die Bewertung, ob das Modell die Wirklichkeit auch abbildet. Man versucht hier mit entsprechenden Testdatensätzen das Modell auf seine Vorhersagekraft (Qualität, Genauigkeit) zu bewerten.
- Visualisierung der Ergebnisse: Ein ganz wichtiger Teil dieser Phase, ist, dass nicht nur das Modell an sich erstellt wird, sondern auch der Visualisierung der Ergebnisse große Aufmerksamkeit geschenkt wird. Die Ergebnisse müssen so gezeigt werden, dass die Stakeholder diese verstehen und nutzen können. Das entscheidet ganz wesentlich über den Erfolg und ist keine triviale Aufgabe. Hier sollten Spezialisten beigezogen werden und der Einsatz von entsprechenden BI-Lösungen (PowerBI, Tableau) ist unbedingt zu empfehlen.
Phase 5: Evaluation – Bewertung und Interpretation der Ereignisse
Der letzte Schritt vor dem endgültigen Einsatz des Systems muss eine Validierung des Modells sein.
- Validierung der Ergebnisse: Es wird bewertet, inwieweit das Modell die Projektziele erreicht. Kommt man hier zu einem negativen Ergebnis, müssen die Gründe gefunden werden und es geht die Phasen zurück um jeweils neu einzusteigen.
- Bewertung des Prozesses: Das Data Mining-Projekt wird rückblickend bewertet. Es wird festgestellt, ob alle wichtigen Faktoren betrachtet wurden und inwieweit die Attribute für zukünftige Data Mining-Projekte zu nutzen sind. Auch sollte man klären, was sich am Prozess verbessern lässt. Der hier gezeigt Abfolge des Prozesses ist als Framework zu sehen. Die Detaillierung der Prozessinhalte ist sehr individuell und vom Reifegrad der Organisation abhängig.
- Nächste Schritte festlegen: In diesem Schritt entscheidet der Projektleiter, ob das Projekt beendet ist und eingeführt wird, oder weitere Anpassungen / Veränderungen vorgenommen werden.
Phase 6: Deployment – Anwendung der Ergebnisse
Die Deployment-Phase gibt das Data Mining-Modell zur Nutzung frei. Die Stakeholder können das Modell nutzen und für die Erfolgsbewertung und Entscheidungsfindung heranziehen. Es bleibt dabei aber schon notwendig, das Modell immer wieder auf seine Qualität zu hinterfragen. Die Welt verändert sich heute schnell und so „veraltern“ oft auch Datenmodelle schnell und verlieren an Qualität oder überhaupt ihre Relevanz. Die Messung der Vorhersagekraft eines Modells muss deshalb ständig gemacht werden, diese Qualitätsbeurteilung muss eine fester Bestandteil des Data-Mining-Modells selbst sein.

Data Manager, Requirements-Engineer, Business Manager, Data-Scientist, Business Model Designer, Compliance Manager, Innovator, Sachverständiger, Allrounder
+43 660 / 24 02 033
manfred.brunner@electronic-consulting.at




