
Titelbild: Image by Pexels from Pixabay
Viele genießen es wohl heute in ein großes Einkaufszentrum zu fahren und einzukaufen. Man weiß, dass man praktisch alle notwendigen Dinge an einem Ort findet. Man kennt den Weg zum Einkaufszentrum, kennt das Parkhaus und den Ort an dem die Einkaufswägen zu finden sind und überall ist Kreditkartenzahlung möglich. Ein Datawarehouse ist nichts anderes. Ein Dateneinkaufszentrum, an dem alle wichtigen Daten im Unternehmen zu finden sind, spezielle aufbereitet für die nachfolgenden Nutzer. Es gibt eine Datenstraße (Datenschnittstelle) dorthin und man findet die Daten strukturiert und normiert (innerhalb des Unternehmens) vor. Sie sind schnell und einfach visualisierbar und entfalten so ihren Nutzen für den Anwender in datengetriebenen Entscheidungsprozessen. Genau das ist die Kernaufgabe eines Datawarehouses. Es soll Daten aus den verschiedensten strukturierten und unstrukturierten Datenquellen einlesen, bereinigen (ungültige, fehlerhafte Datensätze ausscheiden), aufbereiten und über definierte Datenschnittstellen zur Verfügung stellen. Data Engineer und Data Scientist arbeiten zusammen und bauen das Warehouse, dass einen standardisierten Bauplan (Staging – Cleansing – Core – Marts) aufweist und so für ein neues Verständnis im Unternehmen im Umgang mit Daten führt.
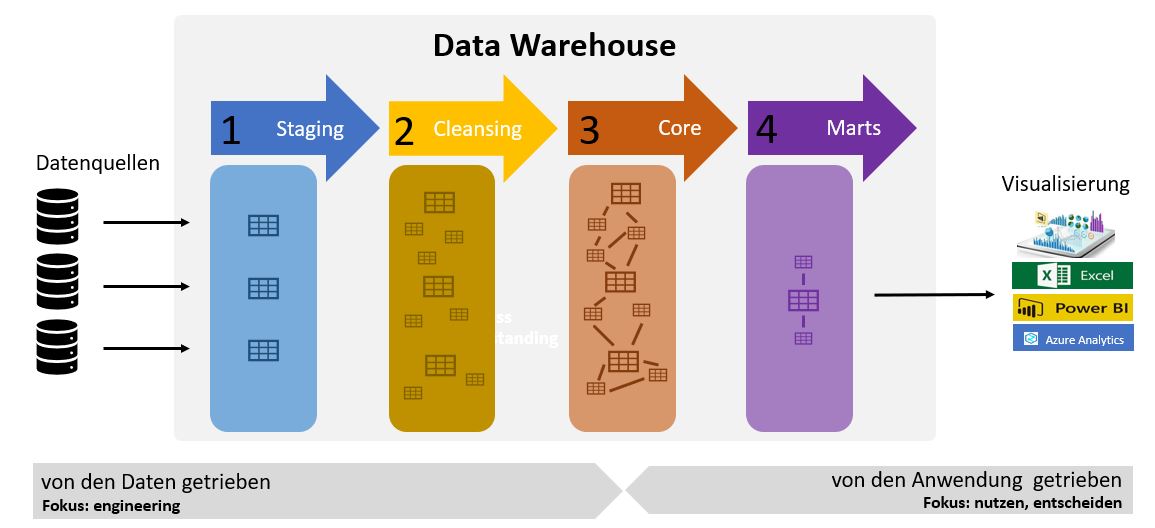
Das Bild zeigt den Aufbau eines Datewarehouse mit den 3 beteiligten Domänen:
- Datenquellen: Hier werden die Daten aus unterschiedlichsten Anwendungen im Unternehmen erfasst und auch gespeichert. Die Daten sind manchmal strukturiert, oft unstrukturiert und spezifisch für jedes System zu sehen. Datenquellen sind beispielsweise, CAD-Systeme, ERP- Systeme, CRM-Systeme, Produktionsanlagen und Maschinen, Sensoren unterschiedlichster Art, Marketing-Tools IoT-Telemetrie uvm.
- Datawarehouse: Die Datenfabrik im Unternehmen. Genau um diese Domäne geht es in diesem kurzen Beitrag und das schauen wir uns gleich näher an.
- Visualisierung: Daten müssen so dargestellt werden, dass sie für die Nutzer einfach und schnell erfassbar sind. Dafür nutzt man heute sogenannte BI (Business Intelligence) -Werkzeuge. Bekannt sind PowerBI von Microsoft, Tableau, Microsoft Azure Analytics uvm. Aber auch MS Excel kommt noch zum Einsatz, wenngleich es kein optimales Werkzeug für die Datenvisualisierung ist.

Jetzt machen wir einen Blick auf die Architektur eines Datawarehouses. Eine solche Datenfabrik hat den Zweck, Daten im Unternehmen aus unterschiedlichsten Anwendungen zu sammeln, standardisiert aufzubereiten und den Nutzern für die Extraktion von Wissen zur Verfügung zu stellen. Das Datawarehouse schafft durch die klare Struktur und die unmissverständliche Definition der Inhalte eine einzige Datenwahrheit, die allen Fachbereichen abhängig von ihren Anforderungen zur Verfügung gestellt wird und damit eine fundierte Basis für (datengetriebene) Entscheidungsprozesse liefert. Innerhalb des Datawarehouses finden wir 4 aufeinander aufbauende Datentransformationsebenen, die Wissen aus den Daten extrahieren (Data Mining), und die wir uns nun näher anschauen.
1 STAGING
Daten werden in die Staging Area aus unterschiedlichsten informationstechnischen Systemen im Unternehmen oder auch von außerhalb eingelesen. Ein Snapshot der Daten aus dem Quellsystem wird im Datawarehouse erstellt. Dies erfolgt üblicherweise nicht laufend, sondern in definierten Zeitintervallen (üblicherweise einmal am Tag). Der Grund dafür ist, dass ein Datenzugriff auch ein System belastet, einerseits das Datawarehouse, andererseits das Quellsystem und es zu Überlastung der Systeme mit folglich verlängerten Zugriffszeiten (Wartezeiten) im Betrieb kommen könnte, die man beispielsweise bei einem Auslesen der Daten einmal am Tag an den Randzeiten (oder bei Nacht) eliminiert. Die Struktur der Daten im Staging entspricht weitgehend den Daten der Schnittstelle zum Quellsystem. Beziehungen zwischen den einzelnen Tabellen aus unterschiedlichen Quellsystemen bestehen erstmals nicht. Auch werden hier Daten aus Vortagen immer wieder überschrieben. Man findet immer die intervallaktuellen Daten (z.B. Daten des Tages)
Überträgt man beispielsweise die Staging Area auf den Ablauf in einem realen Unternehmen, so wäre die Funktion dieser Ebene der Wareneingang. Der Lieferant (Quellsysteme) liefert seine Waren (Daten) an und dort werden immer nur die neuesten Lieferungen bei der Warenanlieferung zwischengelagert, bevor sie geprüft und eingelagert werden.
2 CLEANSING
Cleansing spricht man „klensing“ aus. Bevor die gelieferten Daten ins Core geladen werden, müssen sie geprüft und gegebenenfalls bereinigt werden. Nicht korrekte Daten müssen ausgefiltert, korrigiert oder durch Defaultwerte ersetzt werden. Auch Datentransformationen sind schon Teil dieser Ebene. Dazu gehört beispielsweise die Währungsumrechnung, die Umrechnung in andere SI-Einheiten usw. Es wird hier danach getrachtet einen normierten Datensatz zu erstellen, welcher dann ordentlich ohne Fragezeichen weiterverarbeitet wird. Was hier noch nicht gemacht wird, ist die Herstellung von Verbindungen zwischen Datensätzen bzw. Tabellen.
In unserem Bezug zu einem Unternehmen ist die Cleansing Area Waren (Daten) für die Verarbeitung für die Einlagerung vorzubereiten. Die Waren werden ausgepackt, es wird eine Qualitätskontrolle durchgeführt.
3 CORE

Im Core werden die qualitativ geprüften und bereinigten Daten aus der Cleansing Area zusammengeführt. Die Tabellen werden, wenn Abhängigkeiten bestehen verbunden und thematisch gegliedert. Thematische zusammengefasste Datenbereiche werden „Subject Areas“ genannt. Hier müssen schon die Anforderungen der Kunden mitberücksichtigt werden. Auch Berechnungen (sogenannte „Measures“) können schon gemacht werden und in die Tabellen integriert werden. Die Daten werden im Core so abgelegt, dass die Abfrage historischer Daten zu einem späteren Zeitpunkt jederzeit möglich ist. Dazu verbleiben sie, entsprechend der Festlegung im Unternehmen über einen längeren Zeitraum (das können Jahre sein) im Core abgelegt und für die Verarbeitung zugänglich. Das Core ist die einzige Datenquelle für die 4. Ebene , dem Marts. Direkte Zugriffe von Benutzern auf das Core sollten möglichst vermieden werden.
In Bezug zu unserem Unternehmen ist das Core das Lager. Die angelieferten und geprüften Waren werden so abgelegt, dass sie jederzeit auffindbar sind, aber der Zugriff darauf ist nur internen Mitarbeitern möglich. Kunden haben im Lager nichts zu suchen.
4 MARTS
Data Marts ist nun die Ebene in der die Daten aus dem Core so zusammengestellt und aufbereitet werden, dass sie in einer für die Benutzerabfragen geeigneten Form zur Verfügung stehen. Hier ist ganz besonders auf die Nutzeranforderungen Rücksicht zu nehmen, und es muss ganz klar sein, welche Daten und auch Berechnungen („Measures“) aus Daten den Nutzern für die Darstellung und Visualisierung mittels BI-Tools bereitgestellt (deploy) werden. Marts sind thematisch gruppiert für jede Nutzergruppe und jeder Data Mart sollte nur die für die jeweilige Anwendung relevanten Daten bzw. eine spezielle Sicht auf die Daten enthalten. Die Komplexität der Abfragen wird damit massiv reduziert, für die Nutzer vereinfacht und damit die Akzeptanz des Datawarehouse bei den Nutzern erhöht. Gerade bei Neueinführungen von Data Mining in Unternehmen sollten sie besonders den Anforderungen der Nutzer und dem Marts große Aufmerksamkeit zukommen lassen. Hier entscheidet sich oft der Erfolg eines Systems!
In unserem Unternehmen ist Data Marts die Produktion. Aus den angelieferten Waren wird ein definiertes Produkt gebaut, mit definierten Eigenschaften und definiertem Kundennutzen. Und der Nutzen ist das extrahierte Wissen aus den Daten.
FAZIT
Ein professionell gebautes und ordentlich betriebenes Datawarehouse schafft eine hochqualitative Wissensproduktion, die ein datengetriebenes Unternehmen ermöglichen. Der Aufbau, die Architektur eines solchen Datawarehouses ist völlig branchenunabhängig und kann vom Kleinbetrieb bis zum Großkonzern als Basis dienen. Staging und Cleansing definieren dabei die technische Ebene. In diesen Ebenen ist der Fokus das Engineering gerichtet und es geht darum die Datenqualität hoch zu halten. Im Core und Marts wandert der Fokus zum Kundennutzen und es werden die Datenstrukturen in Abhängigkeit der Anforderungen der Nutzer bereitgestellt.

Data Engineer, Data Scientist, KI-Designer, Requirements Engineer, Elektroniker, Sachverständiger, Manager
+43 660 24 02 033




